Analysing Dataset Using KNN


In this article, I will explain a classification model in detail which is a major type of supervised machine learning. The model we will work on is called a KNN classifier as the title says. The KNN classifier is a very popular and well known supervised machine learning technique. This article will explain the KNN classifier with a simple but complete project.
What is a supervised learning model?
I will explain it in detail. But here is what Wikipedia has to say: Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. Supervised learning models take input features (X) and output (y) to train a model. The goal of the model is to define a function that can use the input features and calculate the output. I will show a practical example with a real dataset
KNN Classifier
The KNN classifier is an example of a memory-based machine learning model. That means this model memorizes the labelled training examples and they use that to classify the objects it hasn’t seen before. The k in KNN classifier is the number of training examples it will retrieve in order to predict a new test example.
KNN classifier works in three steps:
1.When it is given a new instance or example to classify, it will retrieve training examples that it memorized before and find the k number of closest examples from it.
2.Then the classifier looks up the labels (the name of the fruit in the example above) of those k numbers of closest examples.
3.Finally, the model combines those labels to make a prediction. Usually, it will predict the majority labels.
Data Preparation
Before we start, I encourage you to check if you have the following resources available in your computer:
- Numpy Library
- Pandas Library
- Matplotlib Library
- Scikit-Learn Library
- Jupyter Notebook environment.
Download the dataset. I provided the link at the bottom of the page. Run every line of code yourself if you are reading to learn this. First, import the necessary libraries:
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
For this tutorial, I will use the Titanic dataset from Kaggle. Here is how I can import the dataset in the notebook using pandas.
titanic = pd.read_csv('titanic_data.csv')
titanic.head()
#titaninc.head() gives the first five rows of the dataset.
#we will print first five rows only to examine the dataset.
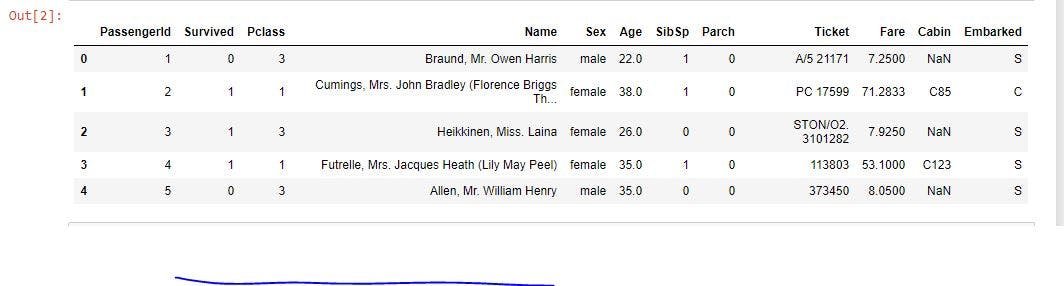
Look at the second column. It contains the information, if the person survived or not. 0 means the person survived and 1 means the person did not survive. For this tutorial, our goal will be to predict the ‘Survived’ feature. This dataset is very simple. Just from intuition, we can see that there are columns that cannot be important to predict the ‘Survived’ feature. For example, ‘PassengerId’, ‘Name’, ‘Ticket’ and, ‘Cabin’ does not seem to be useful to predict that if a passenger survived or not. I will make a new DataFrame with a few key features and name the new DataFrame titanic1.
titanic1 = titanic[['Pclass', 'Sex', 'Fare',
'Survived']]
The ‘Sex’ column has the string value and that needs to be changed. Because computers do not understand words. It only understands numbers. I will change the ‘male’ for 0 and ‘female’ for 1.
titanic1['Sex'] = titanic1.Sex.replace({'male':0,
'female':1})
This is how the DataFrame titanic1 looks like:
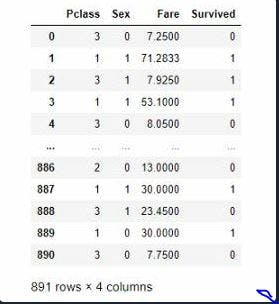
Our goal is to predict the ‘Survived’ parameter, based on the other information in the titanic1 DataFrame. So, the output variable or label(y) is ‘Survived’. The input features(X) are ‘P-class’, ‘Sex’, and, ‘Fare’.
X = titanic1[['Pclass', 'Sex', 'Fare']]
y = titanic1['Survived']
KNN Classifier Model
To start with, we need to split the dataset into two sets: a training set and a test set. We will use the training set to train the model where the model will memorize both the input features and the output variable. Then we will use the test set to see that if the model can predict if the passenger survived using the ‘P-class’, ‘Sex’, and, ‘Fare’. The method ‘train_test_split’ is going to help to split the data. By default, this function uses 75% data for the training set and 25% data for the test set. If you want you can change that and you can specify the ‘train_size’ and ‘test_size’. If you put train_size 0.8, the split will be 80% training data and 20% test data. But for me the default value 75% is good. So, I am not using train_size or test_size parameters.
X_train, X_test, y_train, y_test =
train_test_split(X, y, random_state=0)
Remember to use the same value for ‘random_state’. That way, every time you will do this split, it will take the same data for the training set and test set. I choose random_state as 0. You can choose a number of your choice. Python’s scikit -learn library, already have a KNN classifier model. I will import that.
from sklearn.neighbors import KNeighborsClassifier
Save this classifier in a variable.
knn = KNeighborsClassifier(n_neighbors = 5)
Here, n_neighbors is 5.
That means when we will ask our trained model to predict the survival chance of a new instance, it will take 5 closest training data. Based on the labels of those 5 training data, the model will predict the label of the new instance. Now, I will fit the training data to the model so that model can memorize them.
knn.fit(X_train, y_train)
You may think that as it memorized the training data it can predict the label of 100% of the training features correctly. But that’s not certain. Why? Look, whenever we give input and ask it to predict the label it will take a vote from the 5 closest neighbors even if it has the exact same feature memorized. Let’s see how much accuracy it can give us on training data
knn.score(X_train, y_train)
The training data accuracy I got is 0.83 or 83%.
Remember, we have a test dataset that our model has never seen. Now check, how much accurately it can predict the label of the test dataset. knn.score(X_test, y_test)
The accuracy came out to be 0.78 or 78%.
Congrats! You developed a KNN classifier!
Notice, the training set accuracy is a bit higher than the test set accuracy. That’s overfitting.
What is Overfitting?
In a single sentence, when the training set accuracy is higher than the test set accuracy, we call it overfitting.
Prediction
If you want to see the predicted output for the test dataset, here is how to do that:
Input:
y_pred = knn.predict(X_test)
y_pred
Output:
Or you can just input one single example and find the label. I want to see when a person is traveling in ‘P-class’ 3, ‘Sex’ is female that means 1, and, paid a ‘Fare’ of 25, if she could survive as per our model.
Input:
knn.predict([[3, 1, 25]])
Remember to use two brackets, because it requires a 2D array
Output:
array([0], dtype=int64)
The output is zero. That means as per our trained model the person could not survive.
Please feel free to try wth more different inputs like this one!
If You Want to See Some Further Analysis of KNN Classifier
KNN classifier is highly sensitive to the choice of ‘k’ or n_neighbors. In the example above I used n_neighors = 5. For different n_neighbors, the classifier will perform differently. Let’s check how it performs on the training dataset and test dataset for different n_neighbors value. I choose 1 to 20. Now, we will calculate the training set accuracy and the test set accuracy for each n_neighbors value from 1 to 20.
Input:
training_accuracy = []
test_accuracy = []
for i in range(1, 21):
knn = KNeighborsClassifier(n_neighbors = i)
knn.fit(X_train, y_train)
training_accuracy.append(knn.score(X_train,
y_train))
test_accuracy.append(knn.score(X_test, y_test))
After running this code snippet, I got the training and test accuracy for different n_neighbors. Now, let’s plot the training and test set accuracy against n_neighbors in the same plot. Input:
plt.figure()
plt.plot(range(1, 21), training_accuracy,
label='Training Accuarcy')
plt.plot(range(1, 21), test_accuracy, label='Testing
Accuarcy')
plt.title('Training Accuracy vs Test Accuracy')
plt.xlabel('n_neighbors')
plt.ylabel('Accuracy')
plt.ylim([0.7, 0.9])
plt.legend(loc='best')
plt.show()
Output:
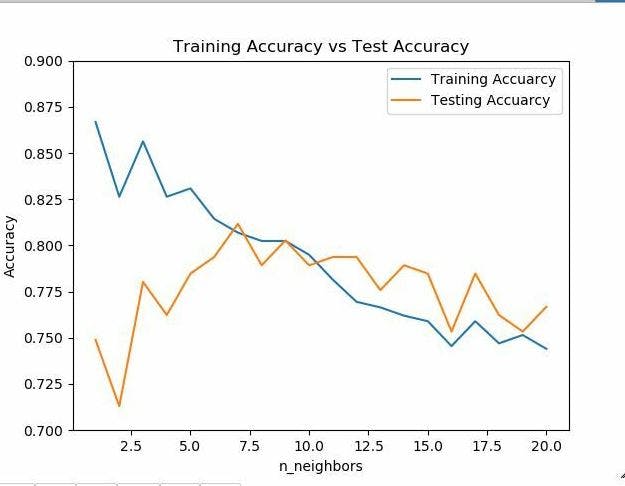
Analyze the Graph Above In the beginning, when the n_neighbors were 1, 2, or 3, training accuracy was a lot higher than test accuracy. So, the model was suffering from high overfitting. After that training and test accuracy became closer. That is the sweet spot. We want that. But when n_neighbors was going even higher, both training and test set accuracy was going down. We do not need that. From the graph above, the perfect n_neighbors for this particular dataset and model should be 6 or 7.
That is a good classifier!
Look at the graph above! When n_neighbors is about 7, both training and testing accuracy was above 80%.
Conclusion
This article’s purpose was to show a KNN classifier with a project. If you are a machine learning beginner this should help you learn some key concepts of machine learning and the workflow. There are so many different machine learning models out there. But this is the typical workflow of a supervised machine learning model.
Here is the titanic dataset I used in the article: kaggle.com/biswajee/titanic-dataset